

Open Data for Experimental Mechanics: From idea to project
This is a cross-post from opendataexpmechanics.github.io. The original post is at opendataexpmechanics.github.io. The purpose of this post is to introduce a new open source project I will be working on during the next year with Patrick Diehl.
Context and background
Patrick and I, Ilyass, met in March 2015 through Twitter. We started exchanging about Peridynamics, a novel theory for modelling of materials in mechanics. I was, and still am, extremely interested in that theory as it appeared to be a theory upon which a model could be built to perform simulation of some complex experiments I was working on. We started working around this theory, I went to Patrick’s lab in Germany as an invited researcher, and Patrick is now a fellow in the laboratory I am part of at Polytechnique Montreal.
In our every day work, I mostly do experimental work, I set up experiments involving several materials being pulled and broken apart while measuring displacements and loads; Patrick, on the other hand, mostly focuses on programming and implementing models to perform the best possible simulations of the experiments I setup in the laboratory. It is through this workflow that we started realizing that other publications about similar experiments did not contain enough information to completely model the experiment or reproduce it. The complete raw experimental data is usually not available, and, when it is possible to get the raw data, it is quite hard to work with since there is no standardized format to present that data. The experiments we do in the laboratory also started to appear less and less valuable, the only thing that appeared to be really valuable are the publications which could be written out of the experimental data.
A few weeks ago, we heard of the Mozilla Science Mini-Grants and decided to try to use this opportunity to setup a project addressing these issues. We worked hard to be able to send a grant demand to the Mozilla foundation and decided to share some of the answers we sent to the foundation in this blog, which will also be used to track the project’s progress.
The issues
The availability of experimental results is limited, because they are scattered in publications. The access to experimental data could be beneficial for mechanical engineers and computational engineers to improve their research. In publications details necessary to reproduce the experiment or design the simulation for a benchmark are often missing. A platform is therefore needed to share experimental data sets in mechanics, rating it with respect to reproducibility and quality of the experimental setup for benchmarks with simulation results. Thus, both communities could enhance the understanding of material behavior and fasten their research.
First project description
Accessible reliable and fully described experimental data is critically lacking in the materials/mechanics community to validate accurate predictive models. Our project proposes a platform for researchers to present their experimental results as standardized datasets. Experimental researchers can then obtain a DOI for their datasets, making them citable by others.
Coming up with a solution
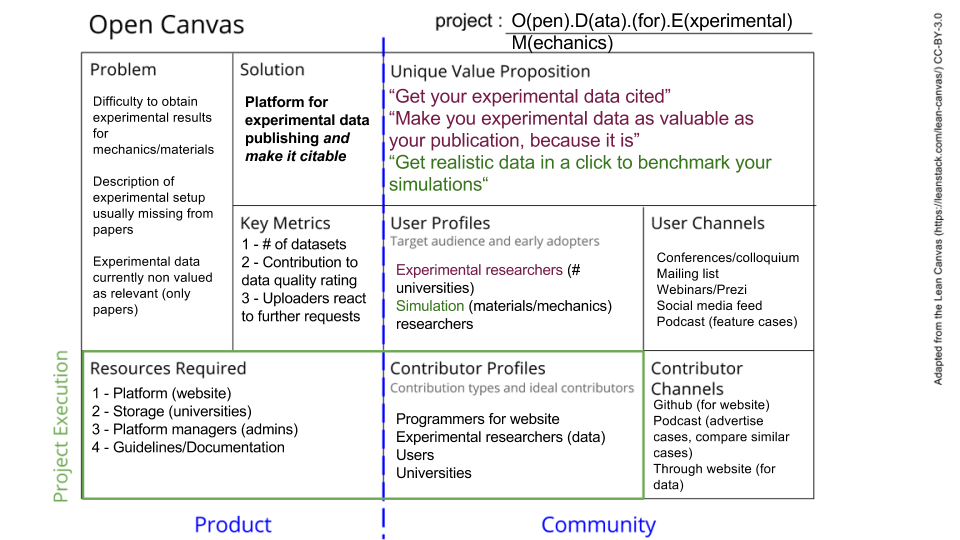
We used the Open Canvas designed by the Mozilla Foundation to try to clearly define the project we would work on. The canvas helps linking a product, which solves a problem, to users and contributors. Contributors are critical for any open source project, which is why they are included in this canvas. The canvas summarizes the whole project’s purpose.
Users
Experimental engineers will benefit from sharing their results by getting citations. It could be a motivation to provide their data on our platform. Computational engineers could use this data as benchmarks for their simulations and rating the data could improve the quality and make it more valuable for the community.
Description of the platform
The current form we have in mind for the project is a web platform. The platform itself will be a repository for datasets for experimental mechanics and materials. Users will be able to upload a PDF document clearly explaining the experiment and the data format. The experiment’s raw data itself will be either stored on our servers, if the total size is not too large, or stored on a University’s servers and linked to them. Other users will be able to login and research through the datasets available by category, kind of tests, materials and other classifiers to be determined later. The data can directly be downloaded by the user.
Planning
- Phase 1 - Initial platform development
During the next months, we will firstly be working on developing an initial version of the platform. Once we have a first functional version, we will move to the second phase.
- Phase 2 - Platform/repository launch
The platform’s code will be made public on Github in our repository. The platform will also be officialy launched. At that point, we will start looking for contributors to help us develop the platform and include new features. We will start advertising the platform to try to get more experimental results available for the users.
- Phase 3 - Sustaining the platform and advertising it
During the last phase, we will keep working on the previously mentionned activities and will also start focusing on means to make the platform sustainable. We will also focus on monitoring the platform to measure and quantify the outputs to see if we are reaching the objectives we defined at the beginning of the project.
If you liked this post, you can share it with your followers or follow me on Twitter!