

Exploring the evolution of Open Access publications with Arcas
Arcas is a python tool designed to help with collecting academic articles from various APIs. This means that you can use Arcas from python (or the terminal) in order to quickly search and collect publications based on detailed queries. Currently, Arcas supports IEEE, PLOS, Nature, Springer and arXiv.
I actually found about Arcas more than a year ago and was eager to try it out but could not find the time to do so. Recently, I have been working on publications that aims at exploring the publication, open source software and experimental data publishing. I’ve been using get_papers, which is a part of the CORE tool chain or mostly scripts I wrote myself to interact with arXiv, IEEE or Elsevier’s API (elsapy), but I decided to try Arcas and share my notes while doing so here.
Arcas is being developed and maintained by Nikoleta Glynatsi, who’s doing a pretty good job at it. The documentation is pretty exhaustive, and the code is commented. I will be focusing on interacting with Arcas through python mostly as I am interested in manipulating the data once we receive it. Let’s go ahead and install the package in a clean virtual environment:
ilyass@tx1:~/Temp/test_arcas$ python3 -m venv .env
ilyass@tx1:~/Temp/test_arcas$ source .env/bin/activate
(.env) ilyass@tx1:~/Temp/test_arcas$ pip install arcas
We’re now ready to play a bit with Arcas. Let’s first open a python interactive console and try the first step of the Arcas documentation in order to check that everything is working fine:
(.env) ilyass@tx1:~/Temp/test_arcas$ python
Python 3.6.8 (default, Apr 9 2019, 04:59:38)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import arcas
>>> api = arcas.Arxiv()
>>> parameters = api.parameters_fix(title='composites', abstract='composites', records=10)
>>> url = api.create_url_search(parameters)
>>> request = api.make_request(url)
>>> root = api.get_root(request)
>>> raw_articles = api.parse(root)
We first import arcas in this example and create an api object for the Arcas Arxiv API. We can then define parameters for our query. In this example, I have specified conditions for the title and abstract fields of our query. It is also possible to specify conditions for the author, year, journals and other fields. The complete list is available in the search fields category of the documentation.
I have also specified that we would like to retrieve the 10 first articles returned by this query. This example is pretty much what the documentation shows. Let’s take a look at the result we get from arcas, raw_articles:
>>> len(raw_articles), type(raw_articles)
(10, <class 'list'>)
The result is a list that contains 10 elements, we can guess that these are the 10 records we requested. If we print one of them (using print(raw_articles[2]) for example), the result we’ll see is the raw answer of the API regarding this specific article. Such a result is not easy to read for us as it might be XML, JSON or other structured language used by the API. In addition, each API (IEEE, Nature, Springer,…) will have their own format through which they will send us their answer. This is really not convenient as I might want to retrieve papers from several APIs and to be able to explore them all together. This is where Arcas becomes really interesting. Arcas can automatically convert any article from one of the APIs it supports to a pandas object. The api object we have previously created contains a method designed to do so:
>>> article = api.to_dataframe(raw_article[0])
>>> type(article)
<class 'pandas.core.frame.DataFrame'>
>>> article
key unique_key title author abstract date journal provenance
0 Akama1997 172a6c24fff3783f785606bf2931f581 Compositeness Condition Keiichi Akama By solving the compositeness condition, unde... 1997 arXiv arXiv
>>> article.title
0 Compositeness Condition
Name: title, dtype: object
After converting an article to a pandas dataframe, we can easily explore various attributes of each article, such as the title.
If an article has several authors, Arcas will automatically generate a pandas dataframe with several lines, where each line is for one of the authors, for example for the second in this dataset:
>>> article = api.to_dataframe(raw_article[2])
>>> article
key unique_key title author abstract date journal provenance
0 Bellazzini2014 a3f60c11239e469784336afb07fa385f Composite Higgses Brando Bellazzini We present an overview of composite Higgs mo... 2014 arXiv arXiv
1 Bellazzini2014 a3f60c11239e469784336afb07fa385f Composite Higgses Csaba Csáki We present an overview of composite Higgs mo... 2014 arXiv arXiv
2 Bellazzini2014 a3f60c11239e469784336afb07fa385f Composite Higgses Javi Serra We present an overview of composite Higgs mo... 2014 arXiv arXiv
Everything seems to be working fine for me, except that my article dataframe does not have as many columns as the developers seem to have in the first tutorial of the documentation. For example, I could not find a way (yet) to access the open_access column that is specified as being available in the previously linked tutorial and in the results set. After some looking around, I have eventually realized that the documentation and the source code on Github are currently different from the version of the source code available through pip. The pip version is an older version as it does not seem to contain the modifications allowing us to explore various columns from the dataframe such as open_access and a few others. If you would likes to access those fields, you should uninstall Arcas using pip and clone the latest version from the Github repository (that’s what I did), you can then install it using the provided setup.py. Update 2019-11-12: @NikoletaGlyn kindly updated the pip repository after I opened an issue about this, the documentation available in ReadTheDocs is now in sync with the latest versions available through pip or Github. You should be able to access all the columns through the pip version. The pip repository was updated within 18 hours of the creation of the issue.
We are otherwise able to use Arcas to perform queries over a specific API. This is already interesting as we can use Arcas to download articles from a single author and automatically analyze their most used keywords in the title, in the abstract, their publication frequency per year, etc …
Arcas can also be used to retrieve papers from several APIs and can then be used to explore them all together. This usage is detailed in second and third tutorials of the documentation.
I have decided to try to plot the amount of open access article available through some of the APIs for each year. I need to be sure that the open_access column will not return Not available since I have noticed that for the Nature API returned Not available for all publications, which also mean that I will not be able to use Nature for this.
It is possible to explore the source code of each API in Arcas to determine if the developers are expecting it to return something relevant or not. This file is the one that manages the IEEE API for example. Doing so shows that arXiv, IEEE and Springer are the only APIs that should be considered. So, I created a Springer and IEEE API account and used the key with Arcas. I wrote a script that was heavily inspired from the example provided by the developers (also very cool from them to have examples, in addition to a nice documentation and comments).
My script tried to download about 201 publications from arXiv and Springer (I eventually had to remove IEEE as I could not get it to work). The query specified that the title or abstract should be related to “composite”, “carbon” or “fiber” which, I hope, should restrict the result to publications about composite materials made of carbon fibers. I tried to download more than 201 publications but consistently got a 504 error during the Springer API query, so I settled for 201 and decided that it would be a diverse enough sample for tonight. The script is available here, you are going to need matplotlib in addition to Arcas of course.
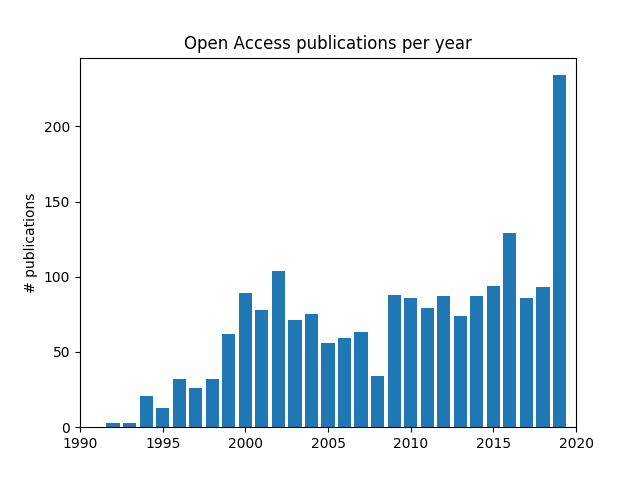
The plot I am showing might seem interesting, as it might show a steady increase in the availability of open access publications through the nineties, an stable consolidation during the 2000s followed by a surprising increase in 2020, which would have been great. However, this plot was made by using about 201 publications from each API of which the arrangement is unknown. Each API returned a set of publications without specifying how those publications were selected. It still seems to be a pretty cool example that shows how a package such as Arcas could be used to explore the publishing ecosystem of your community.
If you liked this post, you can share it with your followers or follow me on Twitter!